
We re coming closer to the
Debian/stretch stable release and similar to what we had with
#newinwheezy and
#newinjessie it s time for #newinstretch!
Hideki Yamane already started the game by blogging about
GitHub s Icon font, fonts-octicons and Arturo Borrero Gonzalez wrote a nice article about
nftables in Debian/stretch.
One package that isn t new but its tools are used by many of us is
util-linux, providing many essential system utilities. We have util-linux v2.25.2 in Debian/jessie and in Debian/stretch there will be util-linux >=v2.29.2. There are many new options available and we also have a few new tools available.
Tools that have been taken over from other packages
- last: used to be shipped via sysvinit-utils in Debian/jessie
- lastb: used to be shipped via sysvinit-utils in Debian/jessie
- mesg: used to be shipped via sysvinit-utils in Debian/jessie
- mountpoint: used to be shipped via initscripts in Debian/jessie
- sulogin: used to be shipped via sysvinit-utils in Debian/jessie
New tools
- lsipc: show information on IPC facilities, e.g.:
root@ff2713f55b36:/# lsipc
RESOURCE DESCRIPTION LIMIT USED USE%
MSGMNI Number of message queues 32000 0 0.00%
MSGMAX Max size of message (bytes) 8192 - -
MSGMNB Default max size of queue (bytes) 16384 - -
SHMMNI Shared memory segments 4096 0 0.00%
SHMALL Shared memory pages 18446744073692774399 0 0.00%
SHMMAX Max size of shared memory segment (bytes) 18446744073692774399 - -
SHMMIN Min size of shared memory segment (bytes) 1 - -
SEMMNI Number of semaphore identifiers 32000 0 0.00%
SEMMNS Total number of semaphores 1024000000 0 0.00%
SEMMSL Max semaphores per semaphore set. 32000 - -
SEMOPM Max number of operations per semop(2) 500 - -
SEMVMX Semaphore max value 32767 - -
lslogins: display information about known users in the system, e.g.:
root@ff2713f55b36:/# lslogins
UID USER PROC PWD-LOCK PWD-DENY LAST-LOGIN GECOS
0 root 2 0 1 root
1 daemon 0 0 1 daemon
2 bin 0 0 1 bin
3 sys 0 0 1 sys
4 sync 0 0 1 sync
5 games 0 0 1 games
6 man 0 0 1 man
7 lp 0 0 1 lp
8 mail 0 0 1 mail
9 news 0 0 1 news
10 uucp 0 0 1 uucp
13 proxy 0 0 1 proxy
33 www-data 0 0 1 www-data
34 backup 0 0 1 backup
38 list 0 0 1 Mailing List Manager
39 irc 0 0 1 ircd
41 gnats 0 0 1 Gnats Bug-Reporting System (admin)
100 _apt 0 0 1
65534 nobody 0 0 1 nobody
lsns: list system namespaces, e.g.:
root@ff2713f55b36:/# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 2 1 root bash
4026531837 user 2 1 root bash
4026532473 mnt 2 1 root bash
4026532474 uts 2 1 root bash
4026532475 ipc 2 1 root bash
4026532476 pid 2 1 root bash
4026532478 net 2 1 root bash
setpriv: run a program with different privilege settings
zramctl: tool to quickly set up zram device parameters, to reset zram devices, and to query the status of used zram devices
New features/options
addpart (show or change the real-time scheduling attributes of a process):
--reload reload prompts on running agetty instances
blkdiscard (discard the content of sectors on a device):
-p, --step <num> size of the discard iterations within the offset
-z, --zeroout zero-fill rather than discard
chrt (show or change the real-time scheduling attributes of a process):
-d, --deadline set policy to SCHED_DEADLINE
-T, --sched-runtime <ns> runtime parameter for DEADLINE
-P, --sched-period <ns> period parameter for DEADLINE
-D, --sched-deadline <ns> deadline parameter for DEADLINE
fdformat (do a low-level formatting of a floppy disk):
-f, --from <N> start at the track N (default 0)
-t, --to <N> stop at the track N
-r, --repair <N> try to repair tracks failed during the verification (max N retries)
fdisk (display or manipulate a disk partition table):
-B, --protect-boot don't erase bootbits when creating a new label
-o, --output <list> output columns
--bytes print SIZE in bytes rather than in human readable format
-w, --wipe <mode> wipe signatures (auto, always or never)
-W, --wipe-partitions <mode> wipe signatures from new partitions (auto, always or never)
New available columns (for -o):
gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID
dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S
bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize
sgi: Device Start End Sectors Cylinders Size Type Id Attrs
sun: Device Start End Sectors Cylinders Size Type Id Flags
findmnt (find a (mounted) filesystem):
-J, --json use JSON output format
-M, --mountpoint <dir> the mountpoint directory
-x, --verify verify mount table content (default is fstab)
--verbose print more details
flock (manage file locks from shell scripts):
-F, --no-fork execute command without forking
--verbose increase verbosity
getty (open a terminal and set its mode):
--reload reload prompts on running agetty instances
hwclock (query or set the hardware clock):
--get read hardware clock and print drift corrected result
--update-drift update drift factor in /etc/adjtime (requires --set or --systohc)
ldattach (attach a line discipline to a serial line):
-c, --intro-command <string> intro sent before ldattach
-p, --pause <seconds> pause between intro and ldattach
logger (enter messages into the system log):
-e, --skip-empty do not log empty lines when processing files
--no-act do everything except the write the log
--octet-count use rfc6587 octet counting
-S, --size <size> maximum size for a single message
--rfc3164 use the obsolete BSD syslog protocol
--rfc5424[=<snip>] use the syslog protocol (the default for remote);
<snip> can be notime, or notq, and/or nohost
--sd-id <id> rfc5424 structured data ID
--sd-param <data> rfc5424 structured data name=value
--msgid <msgid> set rfc5424 message id field
--socket-errors[=<on off auto>] print connection errors when using Unix sockets
losetup (set up and control loop devices):
-L, --nooverlap avoid possible conflict between devices
--direct-io[=<on off>] open backing file with O_DIRECT
-J, --json use JSON --list output format
New available --list column:
DIO access backing file with direct-io
lsblk (list information about block devices):
-J, --json use JSON output format
New available columns (for --output):
HOTPLUG removable or hotplug device (usb, pcmcia, ...)
SUBSYSTEMS de-duplicated chain of subsystems
lscpu (display information about the CPU architecture):
-y, --physical print physical instead of logical IDs
New available column:
DRAWER logical drawer number
lslocks (list local system locks):
-J, --json use JSON output format
-i, --noinaccessible ignore locks without read permissions
nsenter (run a program with namespaces of other processes):
-C, --cgroup[=<file>] enter cgroup namespace
--preserve-credentials do not touch uids or gids
-Z, --follow-context set SELinux context according to --target PID
rtcwake (enter a system sleep state until a specified wakeup time):
--date <timestamp> date time of timestamp to wake
--list-modes list available modes
-r, --reorder <dev> fix partitions order (by start offset)
sfdisk (display or manipulate a disk partition table):
New Commands:
-J, --json <dev> dump partition table in JSON format
-F, --list-free [<dev> ...] list unpartitioned free areas of each device
-r, --reorder <dev> fix partitions order (by start offset)
--delete <dev> [<part> ...] delete all or specified partitions
--part-label <dev> <part> [<str>] print or change partition label
--part-type <dev> <part> [<type>] print or change partition type
--part-uuid <dev> <part> [<uuid>] print or change partition uuid
--part-attrs <dev> <part> [<str>] print or change partition attributes
New Options:
-a, --append append partitions to existing partition table
-b, --backup backup partition table sectors (see -O)
--bytes print SIZE in bytes rather than in human readable format
--move-data[=<typescript>] move partition data after relocation (requires -N)
--color[=<when>] colorize output (auto, always or never)
colors are enabled by default
-N, --partno <num> specify partition number
-n, --no-act do everything except write to device
--no-tell-kernel do not tell kernel about changes
-O, --backup-file <path> override default backup file name
-o, --output <list> output columns
-w, --wipe <mode> wipe signatures (auto, always or never)
-W, --wipe-partitions <mode> wipe signatures from new partitions (auto, always or never)
-X, --label <name> specify label type (dos, gpt, ...)
-Y, --label-nested <name> specify nested label type (dos, bsd)
Available columns (for -o):
gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID
dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S
bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize
sgi: Device Start End Sectors Cylinders Size Type Id Attrs
sun: Device Start End Sectors Cylinders Size Type Id Flags
swapon (enable devices and files for paging and swapping):
-o, --options <list> comma-separated list of swap options
New available columns (for --show):
UUID swap uuid
LABEL swap label
unshare (run a program with some namespaces unshared from the parent):
-C, --cgroup[=<file>] unshare cgroup namespace
--propagation slave shared private unchanged modify mount propagation in mount namespace
-s, --setgroups allow deny control the setgroups syscall in user namespaces
Deprecated / removed options
sfdisk (display or manipulate a disk partition table):
-c, --id change or print partition Id
--change-id change Id
--print-id print Id
-C, --cylinders <number> set the number of cylinders to use
-H, --heads <number> set the number of heads to use
-S, --sectors <number> set the number of sectors to use
-G, --show-pt-geometry deprecated, alias to --show-geometry
-L, --Linux deprecated, only for backward compatibility
-u, --unit S deprecated, only sector unit is supported
 Debconf2020 took place when I was on personal vacations time. But anyway I m lucky enough that my
company, the Wikimedia Foundation, paid the conference registration fee for me and allowed me to
take the time (after my vacations) to watch recordings from the conference.
This is my first time attending (or watching) a full-online conference, and I was curious to see
first hand how it would develop. I was greatly surprised to see it worked pretty nicely, so kudos
to the organization, video team, volunteers, etc!
What follows is my summary of the conference, from the different sessions and talks I watched
(again, none of them live but recordings).
The first thing I saw was the Welcome to Debconf 2020 opening session. It is obvious
the video was made with lots of love, I found it entertaining and useful.
I love it :-)
Then I watched the BoF Can Free Software improve social equality. It was introduced
and moderated by Hong Phuc Dang. Several participants, about 10 people, shared their visions
on the interaction between open source projects and communities. I m pretty much aware of the
interesting social advancement that FLOSS can enable in communities, but sometimes is not so easy,
it may also present challenges and barriers. The BoF was joined by many people from the Asia
Pacific region, and for me, it has been very interesting to take a step back from the usual western
vision of this topic. Anyway, about the session itself, I have the feeling the participants may
have spent too much time on presentations, sharing their local stories (which are interesting,
don t get me wrong), perhaps leaving little room for actual proposal discussions or the like.
Next I watched the Bits from the DPL talk. In the session, Jonathan Carter goes over
several topics affecting the project, both internally and externally. It was interesting to know
more about the status of the project from a high level perspective, as an organization, including
subjects such as money, common project problems, future issues we are anticipating, the social
aspect of the project, etc.
The Lightning Talks session grabbed my attention. It is usually very funny to watch and
not as dense as other talks. I m glad I watched this as it includes some interesting talks, ranging
from HAM radios (I love them!), to personal projects to help in certain tasks, and even some
general reflections about life.
Just when I m writing this very sentence, the video for the
Come and meet your Debian Publicity team! talk has been uploaded. This team does an
incredible work in keeping project information flowing, and social networks up-to-date and alive.
Mind that the work of this team is mostly non-engineering, but still, is a vital part of the
project. The folks in session explain what the team does, and they also discuss how new people can
contribute, the different challenges related to language barriers, etc.
I have to admit I also started watching a couple other sessions that turned out to don t be
interesting to me (and therefore I didn t finish the video). Also, I tried to watch a couple more
sessions that didn t publish their video recording just yet, for example the
When We Virtualize the Whole Internet talk by Sam Hartman. Will check again in a couple of
days.
It is a real pleasure the video recordings from the conference are made available online.
One can join the conference anytime (like I m doing!) and watch the sessions at any pace at any
time. The video archive is big, I won t be able to go over all of it. I won t lie, I still have
some pending videos to watch from last year Debconf2019 :-)
Debconf2020 took place when I was on personal vacations time. But anyway I m lucky enough that my
company, the Wikimedia Foundation, paid the conference registration fee for me and allowed me to
take the time (after my vacations) to watch recordings from the conference.
This is my first time attending (or watching) a full-online conference, and I was curious to see
first hand how it would develop. I was greatly surprised to see it worked pretty nicely, so kudos
to the organization, video team, volunteers, etc!
What follows is my summary of the conference, from the different sessions and talks I watched
(again, none of them live but recordings).
The first thing I saw was the Welcome to Debconf 2020 opening session. It is obvious
the video was made with lots of love, I found it entertaining and useful.
I love it :-)
Then I watched the BoF Can Free Software improve social equality. It was introduced
and moderated by Hong Phuc Dang. Several participants, about 10 people, shared their visions
on the interaction between open source projects and communities. I m pretty much aware of the
interesting social advancement that FLOSS can enable in communities, but sometimes is not so easy,
it may also present challenges and barriers. The BoF was joined by many people from the Asia
Pacific region, and for me, it has been very interesting to take a step back from the usual western
vision of this topic. Anyway, about the session itself, I have the feeling the participants may
have spent too much time on presentations, sharing their local stories (which are interesting,
don t get me wrong), perhaps leaving little room for actual proposal discussions or the like.
Next I watched the Bits from the DPL talk. In the session, Jonathan Carter goes over
several topics affecting the project, both internally and externally. It was interesting to know
more about the status of the project from a high level perspective, as an organization, including
subjects such as money, common project problems, future issues we are anticipating, the social
aspect of the project, etc.
The Lightning Talks session grabbed my attention. It is usually very funny to watch and
not as dense as other talks. I m glad I watched this as it includes some interesting talks, ranging
from HAM radios (I love them!), to personal projects to help in certain tasks, and even some
general reflections about life.
Just when I m writing this very sentence, the video for the
Come and meet your Debian Publicity team! talk has been uploaded. This team does an
incredible work in keeping project information flowing, and social networks up-to-date and alive.
Mind that the work of this team is mostly non-engineering, but still, is a vital part of the
project. The folks in session explain what the team does, and they also discuss how new people can
contribute, the different challenges related to language barriers, etc.
I have to admit I also started watching a couple other sessions that turned out to don t be
interesting to me (and therefore I didn t finish the video). Also, I tried to watch a couple more
sessions that didn t publish their video recording just yet, for example the
When We Virtualize the Whole Internet talk by Sam Hartman. Will check again in a couple of
days.
It is a real pleasure the video recordings from the conference are made available online.
One can join the conference anytime (like I m doing!) and watch the sessions at any pace at any
time. The video archive is big, I won t be able to go over all of it. I won t lie, I still have
some pending videos to watch from last year Debconf2019 :-)
 This post was originally published in the
This post was originally published in the 
 Do you know what s happening in the wires of your network? There is a major
FLOSS player in the field of real time intrusion detection (IDS), inline
intrusion prevention (IPS) and network security monitoring (NSM).
I m talking about Suricata, a mature, fast and robust network threat detection
engine. Suricata is a community driven project, supported by the
Do you know what s happening in the wires of your network? There is a major
FLOSS player in the field of real time intrusion detection (IDS), inline
intrusion prevention (IPS) and network security monitoring (NSM).
I m talking about Suricata, a mature, fast and robust network threat detection
engine. Suricata is a community driven project, supported by the
 I was invited to attend the
I was invited to attend the  Today I noticed the internet buzz about a new alleged Linux malware called
OutlawCountry by the CIA, and
Today I noticed the internet buzz about a new alleged Linux malware called
OutlawCountry by the CIA, and  Most routers/switches out there store their configuration in plain text, which
is nice for backups. I m talking about Cisco, Juniper, HPE, etc.
The configuration of our routers are being changed several times a day by the
operators, and in this case we lacked some proper way of tracking these changes.
Some of these routers come with their own mechanisms for doing backups,
and depending on the model and version perhaps they include changes-tracking
mechanisms as well.
However, they mostly don t integrate well into our preferred version control
system, which is
Most routers/switches out there store their configuration in plain text, which
is nice for backups. I m talking about Cisco, Juniper, HPE, etc.
The configuration of our routers are being changed several times a day by the
operators, and in this case we lacked some proper way of tracking these changes.
Some of these routers come with their own mechanisms for doing backups,
and depending on the model and version perhaps they include changes-tracking
mechanisms as well.
However, they mostly don t integrate well into our preferred version control
system, which is  Debian has many years of history, about 25 years already.
With such a long travel over the continous field of developing our Universal
Operating System, some myths, false accusations and bad reputation has arisen.
Today I had the opportunity to discuss this topic, I was invited to give a
Debian talk in the
Debian has many years of history, about 25 years already.
With such a long travel over the continous field of developing our Universal
Operating System, some myths, false accusations and bad reputation has arisen.
Today I had the opportunity to discuss this topic, I was invited to give a
Debian talk in the  myth #1: Debian is old software
Please, use testing or stable-backports. If you use Debian stable your system
will in fact be stable and that means: updates contain no new software but
only fixes.
myth #2: Debian is slow
We compile and build most of our packages with industry-standard compilers and
options. I don t see a significant difference on how fast linux kernel or
mysql run in a CentOS or in Debian.
myth #3: Debian is difficult
I already discussed about this issue back in
myth #1: Debian is old software
Please, use testing or stable-backports. If you use Debian stable your system
will in fact be stable and that means: updates contain no new software but
only fixes.
myth #2: Debian is slow
We compile and build most of our packages with industry-standard compilers and
options. I don t see a significant difference on how fast linux kernel or
mysql run in a CentOS or in Debian.
myth #3: Debian is difficult
I already discussed about this issue back in
 Debian Stretch stable includes the nftables framework, ready to use.
Created by the Netfilter project itself, nftables is the firewalling tool
that replaces the old iptables, giving the users a powerful tool.
Back in October 2016, I wrote a
Debian Stretch stable includes the nftables framework, ready to use.
Created by the Netfilter project itself, nftables is the firewalling tool
that replaces the old iptables, giving the users a powerful tool.
Back in October 2016, I wrote a 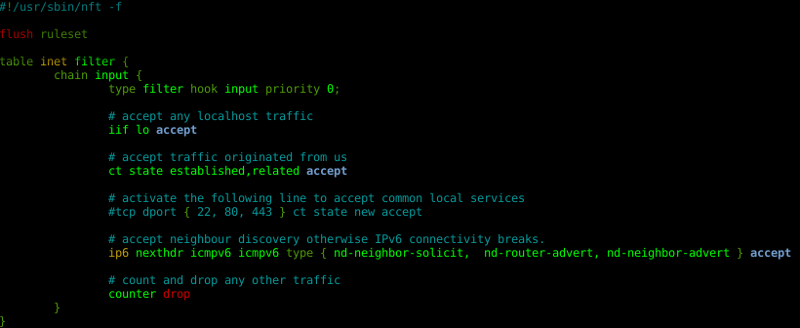 Did you know that the nano editor includes nft syntax highlighting?
Starting with Debian stable Stretch and nftables, packet filtering and network
policing will never be the same.
Did you know that the nano editor includes nft syntax highlighting?
Starting with Debian stable Stretch and nftables, packet filtering and network
policing will never be the same.
 Debian Stretch feels like an excellent release by the Debian project.
The final
Debian Stretch feels like an excellent release by the Debian project.
The final 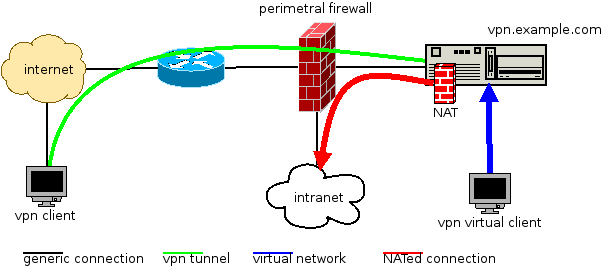

 Today I ended reading an interesting article by the 4th spanish ISP
regarding IPv6 and
Today I ended reading an interesting article by the 4th spanish ISP
regarding IPv6 and 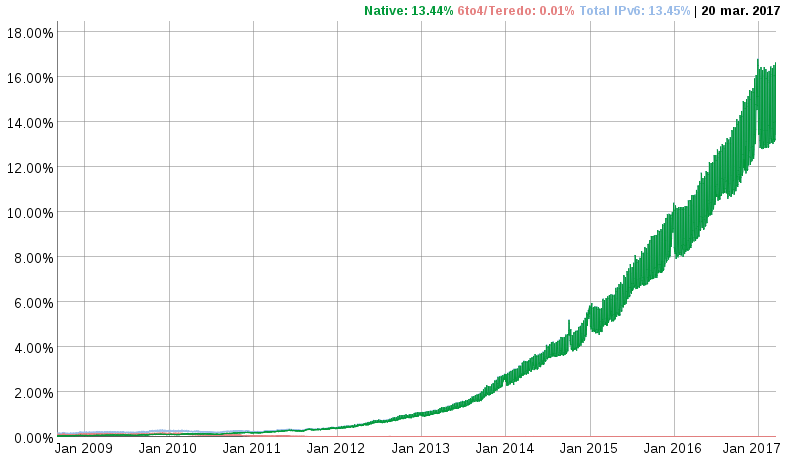 Others ISP operators are giving IPv6 strong precedence over IPv4, that s the case
of Verizon in USA:
Others ISP operators are giving IPv6 strong precedence over IPv4, that s the case
of Verizon in USA:  Great news! The
Great news! The  I was wrong. After the other blog post
I was wrong. After the other blog post  The other day I had to deal with an outage in one of our LDAP servers,
which is running the old Debian Wheezy (yeah, I know, we should update it).
We are running openldap, the slapd daemon. And after searching the log files,
the cause of the outage was obvious:
The other day I had to deal with an outage in one of our LDAP servers,
which is running the old Debian Wheezy (yeah, I know, we should update it).
We are running openldap, the slapd daemon. And after searching the log files,
the cause of the outage was obvious:
{kind=link}
{kind=link}